Not sure how many people here use Max/MSP or Max for Live stuff, but I’m
posting this here for now as a teaser I’m still in the development process. I’m basically building a set of abstractions, tools, and patches for using Sensory Percussion pickups natively in Max (without using the SP software at all).
Here’s a little teaser video showing some of the bits:
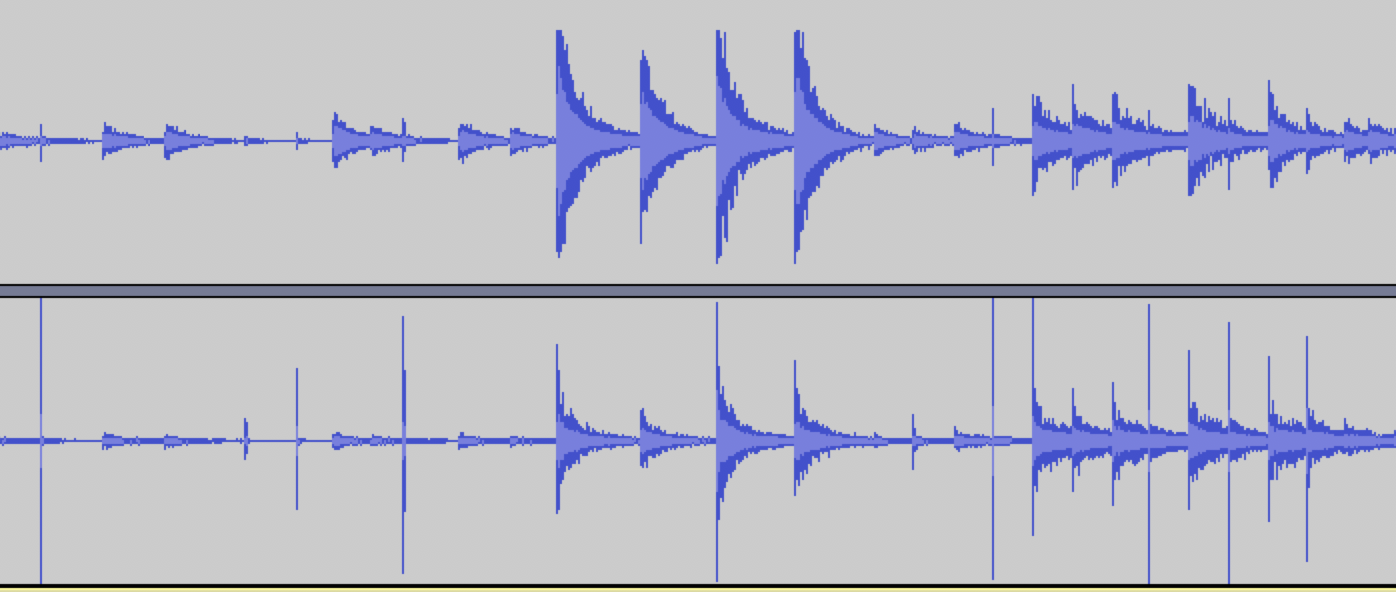
I’ve had a one pickup set for a few years now and never really implemented it in a meaningful way as I found the SP software too limiting (for what I wanted to do), and sending MIDI over from the software to Max was also too limited in terms of resolution. The learning and matching was great, as was the onset detection (press rolls!), but it wasn’t worth the overhead.
Well more recently I got around to just building a bunch of what I want in Max using some machine learning tools as part of a research project I’ve been a part of for a couple of years (FluCoMa).
The video only shows a couple of the bits I’m working on at the moment, but I wanted to just put some floaters out there in case others were interested in this kind of thing.
Things that are currently planned:
- super low latency onset detection (the SP software is about 8-12ms slower, mainly since it has to do all the machine learning funny business)
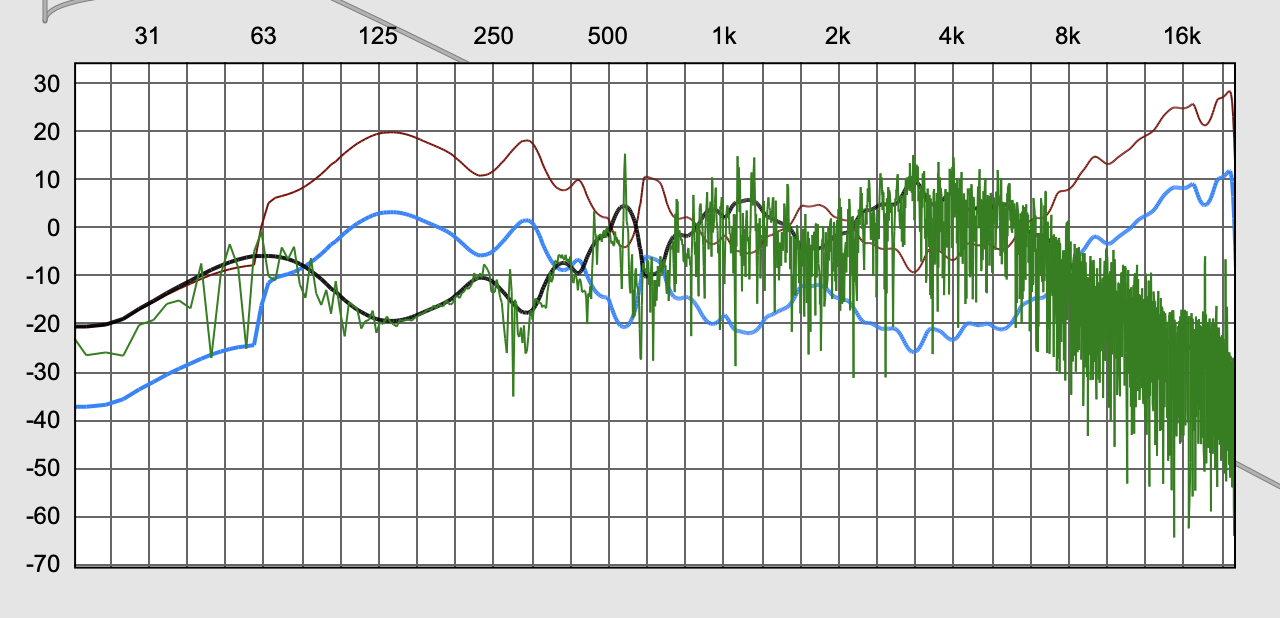
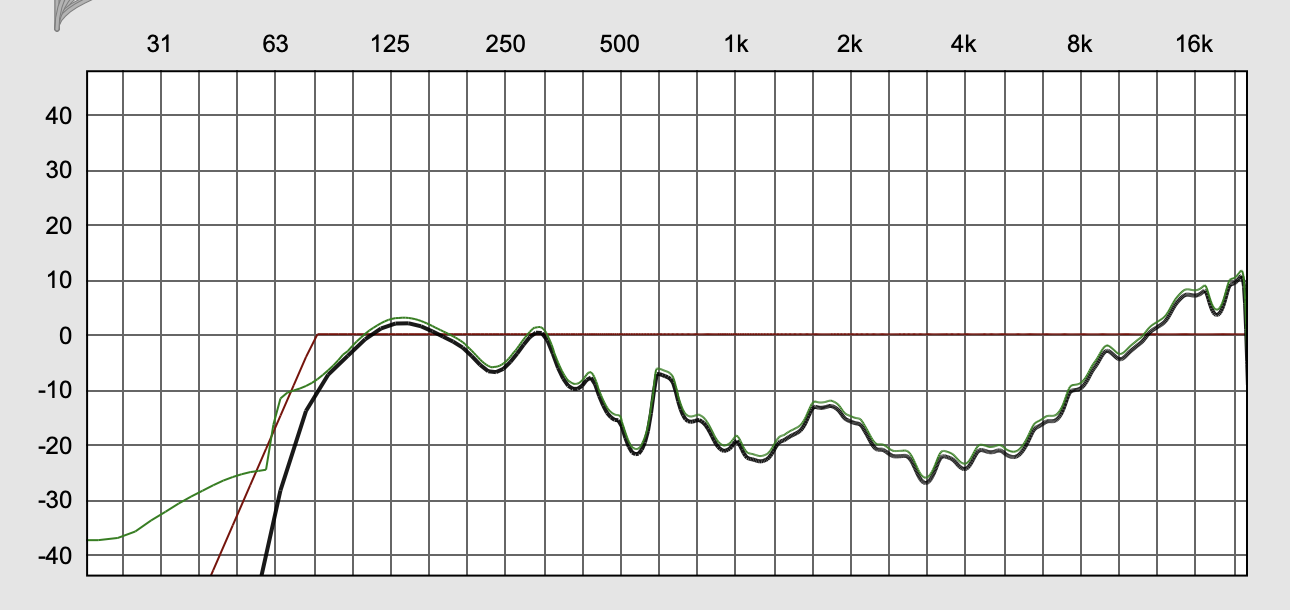
- microphone correction via convolution (so you can use the “audio” from the Sensory Percussion pickup without it sounding terrible)
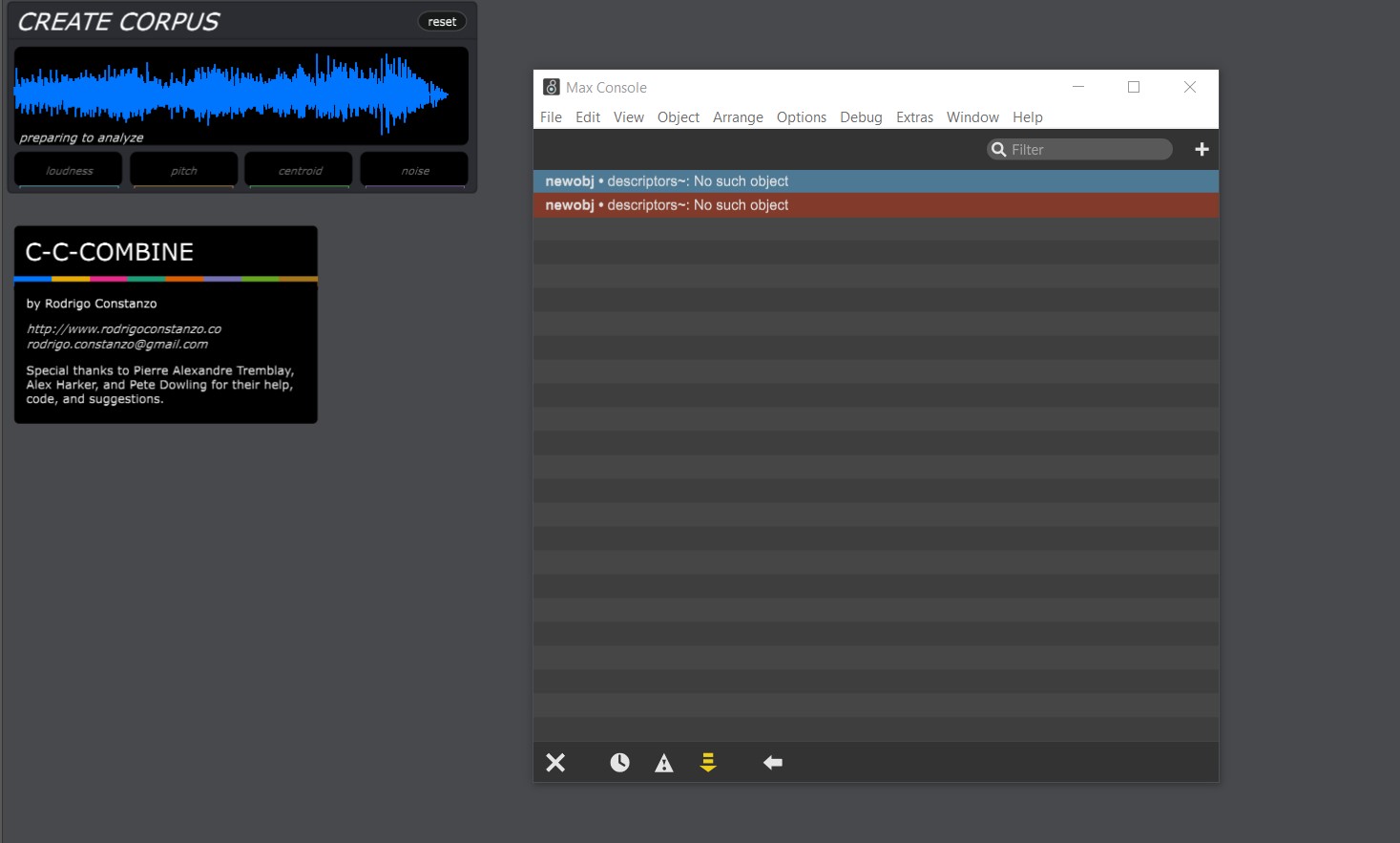
- audio descriptor analysis (this one is huge, as you can map things like “brightness” (spectral centroid) and “noisiness” (spectral flatness) to things, rather than using trained zones which you morph in between, which get broken if you put stuff on/off the drum
- training and matching (like the normal Sensory Percussion software)
- a corpus-based sampler where you can load a huge folder of samples, and then “navigate” via audio descriptors by playing your drum(s) without needing to map specific samples to specific regions
- high-resolution signal-rate control for use with eurorack modules like the ES-8
I’ve got a bunch more utility-type things and other little bits of codes to support stuff as well.
Some of the bits of code will be “ready to use”, including some Max for Live devices, but a lot of it will be building blocks to build more complex and unique things for those that want to explore that side of things.
As soon as I get a few bits built and polished I’ll start posting them to my Github.
Oh, if anyone is curious what all that stuff on my snare is, I’ve been working on loads of extensions to my snare over the years (Kaizo Snare, Transducers).